Decision Tree in Machine Learning
A decision tree is a popular supervised learning algorithm used for making predictions based on input data. It represents a series of decisions in the form of a tree-like structure where:
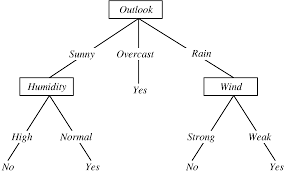
Internal nodes represent attribute tests.
Branches represent the outcomes of these tests.
Leaf nodes represent final decisions or predictions (classes for classification or values for regression).
Decision trees are versatile and can be applied to both classification and regression problems.
Decision Tree Terminologies
Understanding the following terminologies is essential for interpreting and working with decision trees:
- Root Node: The starting point of the decision tree, representing the first attribute split.
- Internal Nodes (Decision Nodes): These nodes represent decisions made based on the values of attributes. Each internal node leads to branches.
- Leaf Nodes (Terminal Nodes): These nodes represent the final outcome (class label or prediction) with no further branches.
- Branches (Edges): Lines connecting nodes, representing the outcome of decisions.
- Splitting: The process of dividing a node into sub-nodes by selecting an attribute and a threshold to partition the data.
- Parent Node: A node that has been split into child nodes.
- Child Node: Nodes created as a result of the split from the parent node.
- Decision Criterion: The rule used to determine how the data is split at a decision node (e.g., information gain or Gini impurity).
- Pruning: The process of removing branches or nodes to prevent overfitting and improve generalization.
How is a Decision Tree Formed?
A decision tree is formed by recursively partitioning the dataset based on the values of attributes. The process involves:
- Selecting the Best Attribute: At each internal node, the algorithm chooses the attribute that best splits the data, usually using metrics like:
- Information Gain (based on entropy) for classification tasks.
- Gini Impurity for classification tasks.
- Variance Reduction for regression tasks.
- Splitting: The chosen attribute is used to divide the dataset into subsets, which are represented by branches. The splitting continues recursively on each subset until a stopping condition is met, such as:
- A predefined maximum depth is reached.
- The number of samples in a node is less than a specified minimum.
- Stopping Criteria: The process stops when further splitting does not improve the model or when the tree reaches a predetermined depth or size.
Why Use Decision Trees?
- Interpretability: Decision trees are easy to interpret and explain, making them useful in applications where human understanding of the model is important.
- Versatility: They work well with both numerical and categorical data, and can solve classification and regression problems.
- Feature Selection: Decision trees automatically perform feature selection by choosing the most informative attributes at each step.
- Visualization: The tree structure provides a clear visual representation of the decision-making process, making it easier to understand the model’s decisions.
Decision Tree Approach
A decision tree uses a hierarchical structure to solve problems:
Each internal node corresponds to an attribute.
Each leaf node corresponds to a class label (for classification tasks) or a numerical value (for regression tasks).
In classification, the decision tree can represent any Boolean function on discrete attributes.
Would you like to dive deeper into specific decision tree algorithms like CART or ID3, or need examples?